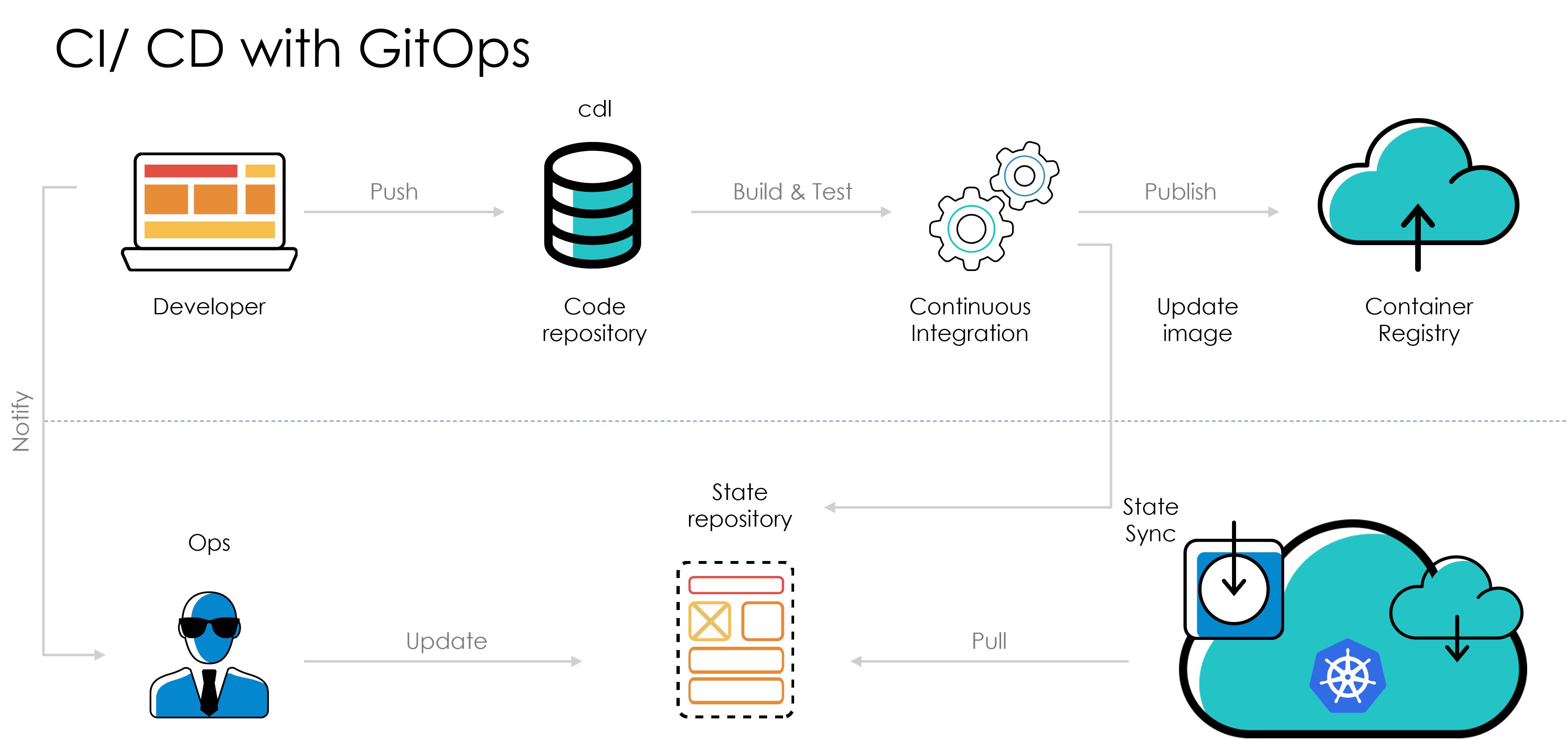
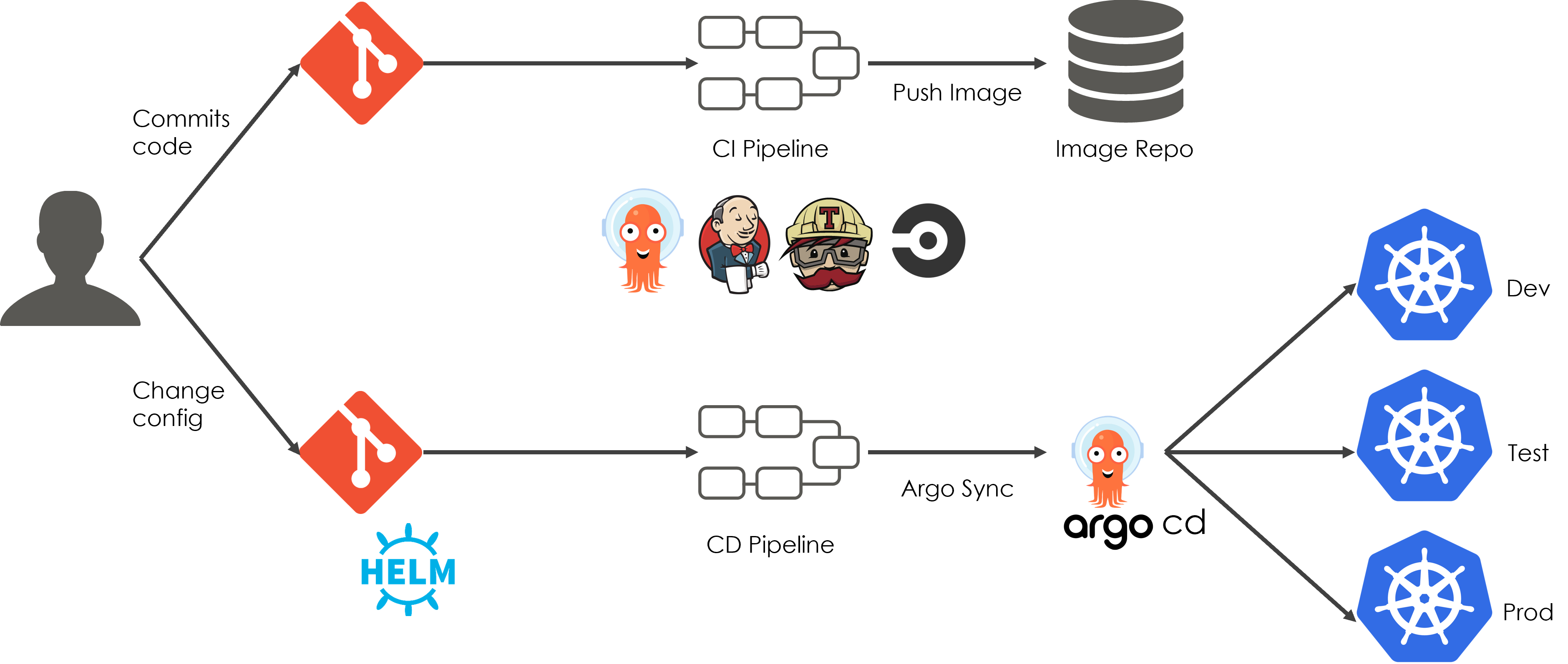
Infrastructure as Code Automation - Single Click Environment Setup: Terraform modules and ansible playbooks were used to automate infrastructure provisioning and environment setup (application components as helm charts deployed on EKS) via Jenkins IAC pipelines
Logging & Monitoring - Prometheus and Grafana helm charts were used, and dashboards were saved as json files in GitHub repo to achieve monitoring as code practice. ELK stack was used for centralised logging and visualisation
Here is the list of improvements with overall DevOps automation
1) Separation of 50+ microservices enabled by automated CI/CD helped reduce 10% load per job per service on Jenkins.
2) EC2 VMs migration to EKS resulted in 40% of cost saving with the use of Dynamic slave pod
3) Usage of multi-branch pipelines and Automated PR checks increased developer's productivity and release frequency by 20%. Also resulted in frequent weekly releases as compared to earlier monthly releases.
4) The manual end-to-end environment setup used to take more than a day, but with automated IAC platform the timelines reduced to ~1.5 hours
5) DRY principle, with the use of global terraform modules and groovy shared libraries for Jenkins pipelines helped reduce number of lines of code and complexity in the code with better reusability. Also, reduction in duplicate code reviews by 50%
6) ArgoCD as a Kubernetes native deployment tool enabled application definitions, configurations, declarative and version-controlled environments and automated reconciliation ensuring application always remains in desired state defined in helm charts which can be verified from ArgoCD UI
7) Centralized terraform platform integrated with Jenkins pipelines with security analysis (tfsec), linting, plan review on slack and automated apply post plan approval.
Outcomes
- Built MVP of Meta-Manager to create highly scalable data ingestion framework
- Integrated all known sources of customer data in MAF with GCR process, added 1000+ Data Sources, approx. 3 TB Data
- Data processing: Capability to process 100 MBPS data in Real Time (3.5 PB annually)
- Cost avoidance of AED 5 Mil, estimated future cost saving of AED 5+ Mil over next five years
- 80% improvement in go-to market speed